
|
PROCESS CASE
WRITE and PFORMAT
File formats have changed significantly in SIR/XS from older versions of SIR and are not binary compatible. You need to export databases and tabfiles using your current version of SIR and import these using XS.
The menu system has been updated to reflect the new features.
NAME and EMPLOYEE_NAME are valid standard names. If a name is referenced in lower or mixed case, e.g. Employee_Name it is automatically translated to upper case.
Non-standard names can be used that do not obey these rules in some respect e.g. they contain lower case letters or special characters such as spaces. Specify a non-standard name by enclosing from 1 to 30 characters in curly braces {}. The name can contain any characters except curly braces and no translation is done on it. Non-standard names are stored without the braces and appear in sorted lists at the appropriate sort sequence. For example
{$100 dollars} and {Employee_Name} are valid references to non-standard names.
The extended syntax for names applies to all named entities in SIR/XS. These are:
VARLABSC(1,"{Employee Name}"). The functions that pass names back to the program wrap any non-standard names in curly brackets automatically. However, please note an exception because buffer names have been allowed to have non-standard formats in earlier versions of SIR. In order to maintain compatibility with existing systems using non-standard buffer names that are enclosed in quotes, the BUFNAME function does not wrap curly brackets and the buffer references in commands continue to expect names in quotes without curly brackets.
There may be occasions when you want to create commands or other output using non-standard names and need the brackets. The new STDNAME function checks a name and wraps curly brackets around if it is a non-standard name.
Note: DO REPEAT; The parameter list in a DO REPEAT has always defaulted to a list of NAMES and been converted to UPPERCASE. To prevent text in a parameter list from being converted to uppercase, enclose it in delimiters using either quotes or dollar signs. If you use quotes as a delimiter, these are passed to the substitution as part of the text. If you use dollar signs as the delimiter, these are stripped out before the substitution and the case of the substitution text is preserved. If you need a non-standard name as the substitution text, specify it with curly braces as you would in a program; there is no need for additional delimiters.
GET VARS has been extended to allow the generation of new local variable names by appending a prefix or a suffix to the original record or table variable names. e.g. GET VARS ALL PREFIX 'EMPLOYEE_'
SHORTNAME in the SPSS SAVE FILE procedure. This specifies that long names are truncated to eight characters for compatibility with older versions of SPSS.
WRITE command, or as a delimiter on the misschar clause when the character is a blank.
TO keyword. Use of TO includes all variables from the first to the second.
AS keyword or by following the variable name with the new name in quotes. e.g. S(1) AS SALARY or S(1) 'SALARY'
ALL to use the default procedure variables. This is essentially documentation as it has the same effect as omitting the VARIABLES specification completely.
SPREAD SHEET VARIABLES = (NAME GENDER SSN DIVISION)
TITLE = "EMPLOYEE LOCATION TABLE"
If the list is not enclosed in brackets then the end of the list is reached under three conditions:TABULATE allows new keywords to specify the individual dimensions of a table rather than this being done positionally.Old syntax was:
TABULATE [[Wafer,]Stub,]Header /
OPTIONS
New syntax is:
TABULATE HEADER = (EXP)
STUB = (EXP)
WAFER = (EXP)
OPTIONS
STANDARD SCHEMA that is similar to a RECORD SCHEMA command in that it signifies the start of a set of variable definitions. The set is ended with an END SCHEMA command. Variables are defined using a DATA LIST command together with any of the normal variable definition commands such as MISSING VALUES, VALUE LABELS or VAR RANGES. e.g.
STANDARD SCHEMA
DATA LIST
POSITION * (I1)
SALARY * (I2)
SALDATE * (DATE'MMIDDIYY')
VAR RANGES POSITION (1 18)
SALARY (600 9000)
VAR SECURITY SALARY (30,30)
MISSING VALUES POSITION
TO SALDATE (BLANK)
VALUE LABELS POSITION (1)'Clerk'
(2)'Secretary'
............
VAR LABEL POSITION 'Position'
SALARY 'Salary'
SALDATE 'Date Salary Set'
END SCHEMA
Once a variable has been defined in the standard schema it can be referenced in any normal record definition with the new STANDARD VARS command. The benefit of this is that coding does not have to be repeated for the variable when it occurs in multiple records. Changes to the standard definition (for example updated value labels) are reflected in all the record variables that reference the standard.ACCEPT REC,REJECT REC,COMPUTE,IF and RECODE are not specific to a variable and thus cannot be specified as standard and copied in.STANDARD VARS command optionally allows a variable to be renamed when used in a record e.g.
RECORD SCHEMA 1 EMPLOYEE
DATA LIST
ID 1 - 4 (I2)
NAME 6 - 30 (A25)
GENDER 31 (I1)
MARSTAT 32 (I1)
SSN 33 - 43 (A11)
BIRTHDAY 44 - 51 (DATE'MMIDDIYY')
EDUC 52 (I1)
NDEPENDS 53 - 54 (I1)
CURRPOS 55 - 56 (I1)
STANDARD VARS CURRPOS AS POSITION
RECORD SCHEMA 0 CIR block. This can contain normal variable definition commands. e.g.
TASK NAME Record Definition for CIR
RECORD SCHEMA 0 CIR
DATA LIST
ID * (I2)
MISSING VALUES ID (BLANK)
VAR LABEL ID 'Identification Number'
END SCHEMA
SIR FILE DUMP and the batch data input utilities now support a separate input for CIR variables. That is, SIR FILE DUMP can write a record 0 in an appropriate format and the batch data input utilities can process that record. You can specify input format definitions for the CIR or simply allow these utilities to use default values. Note that when the batch data input utilities process a CIR, they do not expect or support the extended batch data input processing definitions of ACCEPT REC,REJECT REC,COMPUTE,IF or RECODE.
RECORD SCHEMA now allows you to specify a short label for the record type. The label is enclosed in quotes and is up to 78 characters. e.g.RECORD SCHEMA 3 OCCUP 'Position Details'The
RECDOC function with a documentation line number of zero returns the label.
VAR DOC command that allows multiple lines of text to be stored on the schema to describe the variable. e.g.
RECORD SCHEMA 1 EMPLOYEE
VAR DOC CURRPOS The current position is a coded field
using a copy of the standard var POSITION.
It is the most recent permanent position of
the employee.
SEQUENCE CHECK and SEQUENCE COLS commands are obsolete.
TO construct where a sequence of variables has the same definition. e.g.
MISSING VALUES NAME
TO NDEPENDS (BLANK)
The NOTO option on EXPORT or WRITE SCHEMA suppresses the TO constructs.
VARSEQ option on EXPORT or WRITE SCHEMA means that the schema definition for each variable is written as a set, that is all commands that apply to one variable are written, then all commands for the next variable are written, etc. e.g.
VAR LABEL GENDER 'Gender'
VAR RANGES GENDER (1 2)
MISSING VALUES GENDER (BLANK)
VALUE LABELS GENDER (1)'Male'
(2)'Female'
VAR LABEL MARSTAT 'Marital status'
VAR RANGES MARSTAT (1 2)
MISSING VALUES MARSTAT (BLANK)
VALUE LABELS MARSTAT (1)'Married'
(2)'Not married'
RECORD SCHEMA 0 CIR for any case structured database which contain the definitions for all common variables. The only reference needed for common vars in other record definitions is an entry in either the DATA LIST or VARIABLE LIST commands. Specify the keyword COMMON if you want complete definitions for common vars written in individual record definitions where they are referenced.
DATA LIST. VARLIST on EXPORT or WRITE SCHEMA specifies that variable names are written as a VARIABLE LIST command followed by input definitions as an INPUT FORMAT, command. e.g.VARIABLE LIST ID NAME GENDER MARSTAT ... INPUT FORMAT (I4,T6,A25,I1,I1,...
MODIFY SCHEMA command is now simply a synonym for RECORD SCHEMA. The CLEAR commands and EDIT LABELS commands that were specific for a MODIFY SCHEMA are now accepted in a RECORD SCHEMA and behave as before. If a schema exists and a RECORD SCHEMA command references it, then it is updated.
The definition of a variable can be updated with the normal set of definition commands such as MISSING VALUES.
ADD VARS command and can be deleted from the schema with the new DELETE VARS command. The input position or data format of a variable can be modified with the new MODIFY VARS command. These three new commands are similar in syntax to the DATA LIST command and are used in place of it when modifying an existing schema. If a DATA LIST command is submitted, this completely replaces all variables in the existing definition.
The names of variables can be changed with the new RENAME VARS command which changes the names of existing variables while retaining all other definitions
The new DATA FILES command defines either a single data file or multiple data files. The command can be used to create a data file that can be in a different directory from the other database files and named something other than the database name with a .sr3 extension.
The command can be used to create multiple data files based on key values. If the database is a case structured database, the files are primarily defined by case id values. If the database is a caseless database, the files are primarily defined by record types. For example:
DATA FILES 'company.s31'
FROM (500) 'company.s32'
FROM (1000) 'company.s33'
CSV on all five of the data input utilities READ INPUT DATA, ADD RECORDS, UPDATE RECORDS, REPLACE RECORDS and EVICT RECORDS.The input file is a text file with values for each record in a valid CSV format. The fields must be in the correct sequence that matches the sequence of fields on the database record. A file may either contain records for a single record type, in which case, specify the record type on the utility command or may contain multiple record types, in which case the first field on each input record is the record type.
SIR FILE DUMP can now write CSV files and there is a new keyword CSV to specify this. This utility has an additional keyword DPOINT which specifies that explicit decimal points are written for numeric fields.
NOAUTO on the utilities to stop this processing if required.
BLANKUND for READ INPUT DATA, ADD RECORDS and REPLACE RECORDS. BLANKUND specifies that blank numeric fields on the input file result in UNDEFINED on the record. If this option is not specified, then blanks on input for a numeric field result either in a zero value or in a missing value if a BLANK missing value is defined in the schema.
SIR FILE DUMP has a new keyword CIR which specifies that a separate record (type 0) is written containing all common vars. The batch data input utilities recognise record type 0. If input formats have not been defined specifically for the CIR, these utilities automatically allocate columns for fixed format style processing.
The journal file consists of a linked set of entries one entry per update run. Each entry consists of a set of images of updated records in that run. The images consist of before and after images of updated records.
Unload files can contain multiple unloads of the same database and each unload is a linked entry where the entry consists of after images of all the unloaded records.
There is a new JOURNAL ROLLBACK utility that removes updates and is intended for use if an update run is interrupted and does not complete properly.
When a database is connected, its status is checked to see if it was not closed properly when being updated e.g. the system 'crashed' while the database was open for update. If this is found to be the case, you are asked if you wish to automatically recover. If you choose to try to recover, a journal rollback is done.
There are new features in VisualPQL to assist in user processing of journals and unload files. The PROCESS JOURNAL command allows you to get information about the various entries on the file and to select one or more entries to process. When processing through an entry, data records are read in sequence from the earliest to the latest. Within the PROCESS JOURNAL block, a JOURNAL RECORD IS command starts a block that processes a specific record type. This block is given control when a record of that type is read. Within this block, you can use normal VisualPQL to access the data from the journaled record using the record variable names. viz
PROCESS JOURNAL . JOURNAL RECORD IS record_type . PQL access to record variables . END JOURNAL RECORD IS END PROCESS JOURNALThere is a new parameter
SIRUSER that you can specify on start up and this is logged to the journal file whether updates are done as a single user or through Master. This can be obtained when processing the journal and it may be of interest if producing audit trails. This can be set in a VisualPQL program with the new SIRUSER function.
XML has its own standard for names (which is different to SIR/XS) and any names that are generated by this procedure must meet this standard. XML names begin with alphabetic character (or underscore _) and should not start with XML. They are case sensitive and allow letters, numbers plus some special characters but no spaces.
An example bit of XML from within a document might be:
<company>
<person>
<name>John D Jones</name>
<salary>2150</salary>
<birthday>1986</birthday>
</person>
<person>
<name>James A Arblaster</name>
<salary>1500</salary>
<birthday>1981</birthday>
</person>
</company>
XML SAVE FILE ProcedureFILENAME = filename BOOLEAN = (logical expression) MISSCHAR = character SAMPLE = fraction SORT = variable,....It also has a number of specific clauses
ROOT = 'string'
BREAK = break_variable (TAG = 'string',
ATTRIBUTES = (varname (format) ),...), ELEMENTS = (varname (format) ),...)),
break_variable ..........
DTD [= filename]
SCHEMA [= filename]
The XML file consists of a well formed hierarchy and the ROOT is the top-level outermost component of this. This defaults to SIR_XS_ROOT if not specified. Specify a valid XML name as the root that the processing application expects.
The BREAK clause must be specified and determines the hierarchy of the XML document. Each variable listed on the clause means one further level of nesting. The first variable is the outer level. By default the variable name is used as the tag. Specify a TAG = to override this.
There are two ways in which data can be included in a hierarchical level. You can specify individual data ELEMENTS or a set of ATTRIBUTES. Both of these name data variables but they appear in a different way in the output. Elements appear as individually tagged items whereas attributes appear within the start tag. For example, if there are three data variables for a person Name, Salary, Birthday then using elements, the output looks like:
<person> <NAME>John D Jones</NAME> <SALARY>2150</SALARY> <BIRTHDAY>01 15 78</BIRTHDAY> </person> <person> <NAME>James A Arblaster</NAME> <SALARY>2650</SALARY> <BIRTHDAY>12 07 82</BIRTHDAY> </person>Using attributes the output looks like:
<person NAME="John D Jones" SALARY="2150" BIRTHDAY="01 15 78"> </person> <person NAME="James A Arblaster" SALARY="2650" BIRTHDAY="12 07 82"> </person>If designing an XML application from scratch, this may be a matter of style and choice. If supplying a file to an existing application, then it is a matter of matching a specification.
The name of the element or attribute is the variable name. If this does not match the tag required, you can alter this as per the standard method for specifying variable lists in procedures (e.g. S(1) AS SALARY or S(1) 'SALARY'). Specify any formatting to be applied to the data as per the normal formats specified on a WRITE command.
One or two additional files may be produced that describe the XML file written. You can specify a DocumentType Definition or DTD. XML provides an application independent way of sharing data. With a DTD, independent groups of people can agree to use a common DTD for interchanging data. Your application can use a standard DTD to verify that data that you receive from the outside world is valid. You can also use a DTD to verify your own data. If you specify the DTD keyword, the default filename is the name of the main XML file produced with the extension .dtd
XML Schema is an XML based alternative to DTD. You can also produce an XSD file that describes the XML. If you specify the SCHEMA keyword, the default filename is the name of the main XML file produced with the extension .xsd.
Specifying either Schema or DTD changes the header information written to the main XML file and so informs other processes that a descriptive file exists. You may find other applications that process the XML need a certain style of descriptive file.
Example XML procedure
RETRIEVAL /PROGRESS
. PROCESS CASES ALL
. get vars id
. PROCESS RECORD EMPLOYEE
. GET VARS NAME BIRTHDAY SALARY
. PERFORM PROCS
. END PROCESS RECORD
. END PROCESS CASES
XML SAVE FILE
FILENAME = "c:\sirxs\alpha\XML2.XML"
ROOT = 'company'
BREAK = ID (TAG = 'person' ATTRIBUTES = (name salary birthday))
SORT = ID
schema
END RETRIEVAL
DEBUG clause on PROGRAM/RETRIEVAL/SUBROUTINE is altered. The words MONITOR or FULLMONITOR are obsolete. The clause is now:[DEBUG [= name]]PROGRAM or RETRIEVAL, it defaults to SYSTEM.DEBUG
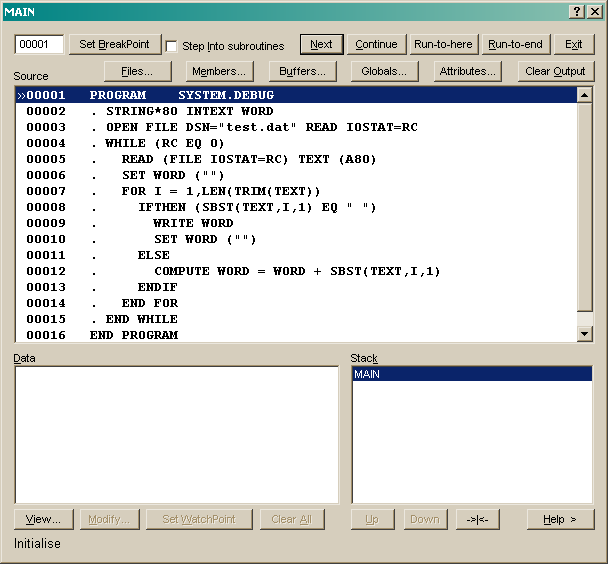
To debug a program, start the GUI debugger from the menu system. This allows you to select a module for debugging and provides various windows to list source code and current position, to set breakpoints, to list variables, inspect and alter values and to set watchpoints and to step through modules, into and out of subroutines.
To start the debugger, first compile a program with the DEBUG keyword then select Debug... from the Program menu. Select the compiled object (SYSTEM.DEBUG:O is the default) from the member list.
From the client point of view processing is as follows:
program
compute rc = serlog ('TONYDELL:4000','')
write rc
compute x = sersend ('PROGRAM')
compute x = sersend ('WRITE "HELLO WORLD"')
compute x = sersend ('END PROGRAM')
compute rc = serexec (1)
write 'rc = ' rc
compute olines = serlines(x)
write 'lines ' olines
for i=1,olines
. compute line = serget (0)
. write line
rof
compute client = serlog ('','')
end program
SERADMIN
Various server administration capabilities (returning numeric values)
SERADMIS
Various server administration capabilities (returning string values)
SEREXEC
Instructs server to execute previously sent commands
SERGET
Gets a line of output from server
SERLINES
Asks server how many lines of output are left
SERLOG
Logs on to the server
SERSEND
Sends a string to the server
SERSENDB
Sends a buffer to the server
SERTEST
Asks server if execution has completed
SERNOOUT
Suppresses server output
SERWRITE
Writes a line of output from server
CLEAR SERVER NOOUTPUT SET SERVER NOOUTPUTThese can be used anywhere in the command stream to selectively control what output is made available for retrieval by the client. SET means that any output directed to standard output is thrown away. If this command is embedded in a PQL program, it affects any compilation listing. Use the
SERNOOUT(n) function for execution time control.
REGEXP searches a string using a regular expression and returns whether the nth occurrence of the string has been found and the position in the string of the start of the match.
REGREP takes a string and two regular expressions and replaces matches from the first expression with text specified by the second.
SEEK function sets a position on an open file.
DTTOTS takes a date and time integer and returns a timestamp. A timestamp is a real*8 representation and is the number of seconds since the start of the SIR/XS calendar. You can do calculations between timestamps and the individual date and time components can be extracted using the TSTODT and TSTOTM functions before using any other date and time functions e.g. for print formatting.
COUNT and SAMPLE options on PROCESS CASE now allow variables and expressions as parameters rather than requiring explicit integer variables.
TITLE on the SCREEN command. This allows you to specify PQL that constructs screen titles on single and multi-page screens.
There is a new sub-clause FONT as part of the PQLForms general clauses that allows specification of non-standard fonts including color. This has also been implemented in the forms screen painter allowing easy use of fonts.
The IF sub-clause has been implemented for FBUTTON which allows the button to be enabled or disabled (greyed out) according to specific conditions.
ENCRYPT [ON |OFF]
ENCRYPT turns on data encryption for this database. This means that all data records in the database are encrypted on disk and are thus protected against scrutiny from software other than SIR/XS. The encryption method used is a version of the publicly available Blowfish algorithm using a 256 bit key.
All data records are encrypted, however keys in index blocks are held in unencrypted format. Do not use names or other recognisable strings as keys if this data is sensitive and requires protection. Unloads and journals for encrypted databases are themselves encrypted. Text files are all unencrypted. Schemas and procedures are unencrypted.
ENCRYPT OFF turns encryption off for a database. Encryption can be turned on and off without ill effect. Records are written according to the current setting; records are read and recognized as to whether they require decryption.
Passwords and security levels are encrypted on all databases. There are encryption/decryption functions in VisualPQL if users need to encrypt data for themselves but these use a user specified key - the SIR/XS system key is used for database encryption.
CRYPTKEY
Sets the key for the encryption functions.
DECRYPT
Decrypts an encrypted string.
ENCRYPT
Encrypts a string.
WRITE command or formatted by PFORMAT have a picture specification that describes the required format. This now has additional capabilities for floating dollar sign and negative numbers. The documentation has been upgraded to cover all picture specification features.
SET IMAGE command to specify a bitmap to use for the button.Images can optionally be centred or resized to fit the image control.
SETRANGE Sets the minimum and maximum possible values for the a slider, spin or progress control.
BRANCH Adds a new node to a tree. The node is added as a child node of the parent.
BRANCHD Deletes the node from a tree.
NBRANCH Returns the number of child nodes of the given node.
BRANCHN Returns the node number of the nth child nodes of the given node.
SCROLLAT Gets a position in a gui scrollable item
SCROLLTO Sets a position in a gui scrollable item
CLIPAPP
Adds text to the clipboard.
CLIPGET
Gets text from the clipboard.
CLIPLINE
Gets count of lines in the clipboard.
CLIPSET
Clears the clipboard and adds text to the clipboard.
message VSCROLL m_id, m_arg1m_id contains the id of the list or text control that has been scrolled;m_arg1 contains the position of the item that is the top most visible in the list.
message RMOUSE m_id, m_arg1, m_arg2
m_id contains the id of the control where the right mouse button was clicked. If the mouse was not over a control then -1 is sent.
The information in m_arg1 and m_arg2 depends on the type of control:
List controls send the position of the item in the list and a double click indicator.
Otherwise the x,y coordinate relative to the top left of the control is returned.
Several values returned by the SYSTEM function have become obsolete and replaced with new codes:
Automatic disconnection of idle master clients. The new SETAKL function (Set AutoKill Limit) allows setting of a time limit for
clients of master. If a client is idle for the given number of minutes then they will be automatically disconnected.
COMPUTE RC = SETAKL(minutes,password)
SIR/XS databases are NOT backward compatible with SIR2002 and earlier but can be exported and re-imported if needed to be used with older versions but the OLD option must be used with the export to avoid creating new schema constructs that are incompatible with earlier versions. (Note. Using specific SIR/XS features such as non-standard names may result in incompatibilities anyway.)
Since SIR/XS now supports non-standard names using {} as delimiters, the use of double quotes in SQL as delimiters for non-standard names is not recommended but is still supported.
Old text style screens are no longer supported in DBMS/VisualPQL. The following text style screen commands are no longer supported:
ACCEPT CHARACTER BELL BOX CURSOR CONNECT TEMPLATE CREATE TEMPLATE DELETE TEMPLATE ERASE TEMPLATE DISPLAY TEXT EXPORT TEMPLATE ERASE SCREEN FIELD INPUT FILL HORIZONTAL MENU KEYPAD ON LINE ATTRIBUTE LINE CHARACTER MAPKEY MODIFY TEMPLATE MOUSE POP TEMPLATE PUSH TEMPLATE PURGE TEMPLATE REFRESH SCREEN RESTORE TEMPLATE SCREEN GRAPHICS SCROLL TEMPLATE SENSE MOUSE SOUND function STORE TEMPLATE VERTICAL MENUForms is still supported although it is not being developed further and does not have constructs to use any database secondary indexes. Forms is now the only component of SIR/XS to use a text style full screen.
The default screen font used in SIR/XS is different to that used in 2002 and this may cause some size differences in dialogs. The font used to be MS Sans Serif but this is no longer included by default in windowsXP and this font doesn't have all the characters available in other fonts (eg "…"). The default font is now Arial. To alter the default font, set sir.fnamm to a fontname either manually by editing the sir.ini file or with
UPSET in the start menu. e.g.
UPSET("sir.fnamm","MS Sans Serif")
This sets the font to be the same as used in SIR2002.
PROMPT execution parameter will cause a prompt to be written to the screen each time an input line is read.