 Database
Database 






|
| Database | | Data |
The normal way to run these interactively is from the Data - File Input menu. These can also be run as commands. The batch data input utilities are :
ADD REC that adds new records if they do not exist;
EVICT REC that deletes existing records;
REPLACE REC that replaces existing records;
UPDATE REC that replaces selected variables on existing records;
INPUT DATA that adds or replaces records.
The batch data input utilities use any COMPUTE,IF,RECODE,ACCEPT or REJECT RECORD IF
clauses defined in the schema for a given record type. While you can use the utilities to input data directly into the CIR (record type zero), these clauses can only be specified at the normal record level even if they refer to common variables.
The FILE DUMP utility writes data from a database to a text file in a format that can be used by the data input utilities.
The FILE LIST utility writes a report showing the data from a database. Naturally this can be fairly voluminous.
You can also display and edit data through the SIR/XS SPREADSHEET utility that selects a set of data, displays it in a familiar spreadsheet style manner and allows you to update the data if necessary.
| |
ADD REC, READ INPUT DATA and REPLACE REC have identical specifications.EVICT REC has fewer options plus one particular keyword.UPDATE REC has all the standard options plus four additional parameters.They all have the same possible five files:
SIR FILE DUMP utility or by the VisualPQL procedure WRITE RECORDS.SIR FILE DUMP, this allows database maintenance without having to assign columns manually. If you are processing a specific input file and want only to process variables with assigned input/output columns, the NOAUTO keyword suppresses this automatic assignment.CSV keyword is specified, then the input file is in Comma Separated Variable (CSV) format. The input file is a text file with values for each record in a valid CSV format. The fields must be in the correct sequence that matches the sequence of fields on the database record. A file may either contain records for a single record type, in which case the record type is specified on the utility command or may contain multiple record types, in which case the first field on each input record is the record type.SIR FILE DUMP utility with the CSV keyword or by the VisualPQL procedure CSV SAVE FILE.
ACCEPT or other option.)
COL DESCRIPTION
-------------------------------
1-4 record number
5-6 message number
1 record number error
2 variable format error
3 variable/compute error
4 variable/recode error
5 ACCEPT REC failed
6 REJECT REC failed
7 record accepted with errors
8 record rejected
7-18 date of run
19-26 time of run
27-30 ordinal of record on this file
31-34 DBMS error number
35-42 variable name, if variable error
43-46 ACCEPT/REJECT REC num, line num
47-50 field starting column
51-54 field ending column
| |
ADD REC adds new records to the database. The keys of incoming records are matched against those already in the database. If an input record matches an existing record, the incoming record is rejected with an error message.
ADD REC INPUT = filename [LISTFILE = filename] [ERRFILE = filename] [LOGFILE = filename] [SUMFILE = filename] [ACCEPT] [ALL] [BLANKUND] [CSV] [LOGALL] [NOAUTO] [NONEW] [NOSEQ] [ALIMIT = n] [BLIP = n] [LOADING = n] [RECTYPE = rectype] [RLIMIT = n] [SKIP = n] [STOP = n]There are three groups of parameters. The first group specifies files, the next group specifies keywords and the last group specifies limits or other conditions. Optionally separate multiple parameters on a command with a slash "/".
FILES
INPUT
LISTFILE
ERRFILE
LISTFILE.
LOGFILE
SUMFILE
SUMFILE and LISTFILE can be the same file in which case the summary report is written after any error listing.Keywords - Use these to specify the particular processing option(s) required:
ACCEPT
ALL
ERRFILE regardless of whether or not they are accepted into the database.
BLANKUND
UNDEFINED on the record. If this option is not specified, then blanks on input for a numeric field either result in a missing value, if a BLANK missing value is defined in the schema, or in a zero value.
CSV
LOGALL
LOGFILE.
NOAUTO
NONEW
Limits and Settings - Specify the keyword followed by an equals sign, "=" , followed by the value for these limits and settings.
ALIMIT = n
BLIP = n
LOADING = .n
RECTYPE = n | name
RECTYPE= keyword may be specified. If omitted, data records are identified by the record number in the columns specified in the schema (or by the first field on a CSV file).
RLIMIT = n
SKIP = n
STOP = n
Example:
ADD REC INPUT = 'INPUT.DAT'
ERRFILE = 'ERR.DAT'
LOGFILE = 'LOG.LST'
LISTFILE = 'OUT.LST'
SUMFILE = 'SUM.LST'
ACCEPT
RECTYPE = 1
| |
EVICT REC INPUT = filename [LISTFILE = filename] [ERRFILE = filename] [LOGFILE = filename] [SUMFILE = filename] [CSV] [EVICTCIR] [LOGALL] [NOAUTO] [BLIP = n] [RECTYPE = rectype] [RLIMIT = n] [SKIP = n] [STOP = n]Deletes records. The keys of input records are matched against those already in the database. If an input record matches an existing record, the existing record is deleted. If an input record does not match an existing record, an error message is written.
There are three groups of parameters. The first group specifies files, the next group specifies keywords and the last group set limits or other conditions. Optionally separate multiple parameters on a command with a slash "/".
FILES
INPUT
LISTFILE
ERRFILE
LOGFILE
SUMFILE
SUMFILE and LISTFILE can be the same file in which case the summary report is written after any error listing.Keywords - Use these to specify the particular processing option(s) required.
CSV
EVICTCIR
LOGALL
LOGFILE.
NOAUTO
Limits and Settings - Specify the keyword followed by an equals sign, "=" , followed by the value for these limits and settings.
BLIP
RECTYPE
RECTYPE= can be specified. If omitted, data records are identified by the record number in the columns specified in the schema (or by the first field on a CSV file).
RLIMIT
SKIP
STOP
Example:
EVICT REC INPUT = 'INPUT.DAT'
ERRFILE = 'ERR.DAT'
LOGFILE = 'LOG.LST'
LISTFILE = 'OUT.LST'
SUMFILE = 'SUM.LST'
RECTYPE = 1
| |
READ INPUT DATA INPUT = filename
[LISTFILE = filename]
[ERRFILE = filename]
[LOGFILE = filename]
[SUMFILE = filename]
[ACCEPT]
[ALL]
[CSV]
[LOGALL]
[NOAUTO]
[NONEW]
[NOSEQ]
[ALIMIT = n]
[BLIP = n]
[LOADING = n]
[RECTYPE = rectype]
[RLIMIT = n]
[SKIP = n]
[STOP = n]
Adds new records and replaces existing records. The keys of incoming records are matched against those already in the
database. If an input record matches an existing record, the existing record is replaced; if the keys do not match, a new record is added.There are three groups of parameters. The first group specifies files, the second group specifies keywords and the last group set limits or other conditions. Optionally separate multiple parameters on a command with a slash "/".
FILES
INPUT
LISTFILE
ERRFILE
LISTFILE.
LOGFILE
SUMFILE
SUMFILE and LISTFILE can be the same file in which case the summary report is written after any error listing.Keywords - Use these to specify the particular processing option(s) required.
ACCEPT
ALL
ERRFILE regardless of whether or not they are accepted into the database.
CSV
BLANKUND
UNDEFINED on the record. If this option is not specified, then blanks on input for a numeric field either result in a missing value if a BLANK missing value is defined in the schema or in a zero value.
LOGALL
LOGFILE.
NOAUTO
NONEW
Limits and Settings - Specify the keyword followed by an equals sign, "=" , followed by the value for these limits and settings.
ALIMIT
BLIP
LOADING
"N" is a number between 0.01 and 0.99. When data is reloaded or imported, blocks are filled. On subsequent update runs, the normal value is 0.5, that means that a full data block is split in half. A value of .99 splits a data block with n records into one data block containing n-1 records and one data block containing 1 record. This is useful if records are added in keyfield order to keep the database file as compact as possible.
RECTYPE
RECTYPE= keyword may be specified. If omitted, data records are identified by the record number in the columns specified in the schema (or by the first field on a CSV file).
RLIMIT
SKIP
STOP
Example:
READ INPUT DATA INPUT = 'INPUT.DAT'
ERRFILE = 'ERR.DAT'
LOGFILE = 'LOG.LST'
LISTFILE = 'OUT.LST'
SUMFILE = 'SUM.LST'
ACCEPT
RECTYPE = 1
| |
REPLACE REC INPUT = filename
[LISTFILE = filename]
[ERRFILE = filename]
[LOGFILE = filename]
[SUMFILE = filename]
[ACCEPT]
[ALL]
[CSV]
[LOGALL]
[NOAUTO]
[NONEW]
[NOSEQ]
[ALIMIT = n]
[BLIP = n]
[LOADING = n]
[RECTYPE = rectype]
[RLIMIT = n]
[SKIP = n]
[STOP = n]
Replaces existing records. The keys of input records are matched against those already in the database. If an input record
does not match an existing record, it is rejected with an error message. If a match is found, the existing record is replaced by the input record.There are three groups of parameters. The first group specifies files, the next group specifies keywords and the last group sets limits or other conditions. Optionally separate multiple parameters on a command with a slash "/".
FILES
INPUT
LISTFILE
ERRFILE
LISTFILE.
LOGFILE
SUMFILE
SUMFILE and LISTFILE can be the same file in which case the summary report is written after any error listing.Keywords - Use these to specify the particular processing option(s) required.
ACCEPT
ALL
ERRFILE regardless of whether or not they are accepted into the database.
CSV
BLANKUND
UNDEFINED on the record. If this option is not specified, then blanks on input for a numeric field either result in a missing value if a BLANK missing value is defined in the schema or in a zero value.
LOGALL
LOGFILE.
NOAUTO
NONEW
Limits and Settings - Specify the keyword followed by an equals sign, "=" , followed by the value for these limits and settings.
ALIMIT
BLIP
LOADING
RECTYPE
RECTYPE= keyword may be specified. If omitted, data records are identified by the record number in the columns specified in the schema (or by the first field on a CSV file).
RLIMIT
SKIP
STOP
Example:
REPLACE REC INPUT = 'INPUT.DAT'
ERRFILE = 'ERR.DAT'
LOGFILE = 'LOG.LST'
LISTFILE = 'OUT.LST'
SUMFILE = 'SUM.LST'
ACCEPT
RECTYPE = 1
| |
UPDATE REC INPUT = filename [LISTFILE = filename] [ERRFILE = filename] [LOGFILE = filename] [SUMFILE = filename] [ACCEPT] [ADD] [ALL] [COMPUTE] [CSV] [LOGALL] [NOAUTO] [NOBOOL] [NONEW] [NOSEQ] [ALIMIT = n] [BLIP = n] [LOADING = n] [MISSCHAR = a] [RECTYPE = rectype] [RLIMIT = n] [SKIP = n] [STOP = n]
Replaces individual variables in existing records. The keys of input records are matched against those already in the database. If a match is found, the variables in the existing record are replaced by non-blank fields in the input. If a match is not found, the input record is rejected with an error message, or, if the ADD keyword is specified, a new record is created.
There are four additional parameters for UPDATE RECORD:
ADD
COMPUTE
COMPUTE statements. By default, COMPUTE statements from the Schema are not re-executed.
NOBOOL
ACCEPT REC IF and REJECT REC IF) are performed. Any temporary variables referenced in the consistency check must be respecified on the input record to assure that the intent of the check is satisfied.
MISSCHAR
UNDEFINED, include this character on the input record in the leftmost column of the variable. A blank does not indicate a missing value and may not be used as the character. There is no default.There are three groups of parameters. The first group specifies files, the next group comprises keywords and the last group sets limits or other conditions. Optionally separate multiple parameters with a slash "/".
FILES
INPUT
LISTFILE
ERRFILE
LISTFILE.
LOGFILE
SUMFILE
SUMFILE and LISTFILE can be the same file in which case the summary report is written after any error listing.Keywords - Use these to specify the particular processing option(s) required.
ACCEPT
ADD
ALL
ERRFILE regardless of whether or not they are accepted into the database.
COMPUTE
COMPUTE specifications in the schema are re-executed.
CSV
LOGALL
LOGFILE.
NOAUTO
NOBOOL
ACCEPT REC IF or REJECT REC IF specifications in the schema are bypassed.
NONEW
Limits and Settings - Specify the keyword followed by an equals sign, "=" , followed by the value for these limits and settings.
ALIMIT
BLIP
LOADING
MISSCHAR
UNDEFINED. When this character is in the leftmost position of a variable on input, the variable on the database is set to undefined. Specify a single character, do not enclose it in quotes.
RECTYPE
RECTYPE= keyword may be specified. If omitted, data records are identified by the record number in the columns specified in the schema (or by the first field on a CSV file).
RLIMIT
SKIP
STOP
Example:
UPDATE REC INPUT = 'INPUT.DAT'
ERRFILE = 'ERR.DAT'
LOGFILE = 'LOG.LST'
LISTFILE = 'OUT.LST'
SUMFILE = 'SUM.LST'
ACCEPT
RECTYPE = 1
MISSCHAR = *
| |
SIR FILE DUMP [FILENAME = fileid]
RECTYPES = {ALL | rectype (log_expr),...}
[BOOLEAN = (log_expr)]
[CIR]
[COUNT = total [,increment[,start]]]
[CSV]
[DPOINT]
[LIST = case id list]
[NOAUTO]
[SAMPLE = fraction [,seed]]
[UNDEFINED = char]
Creates a text file in a form suitable for processing by the batch data input utilities. DBA read security clearance is needed to use this utility.Optionally separate multiple parameters on the command with slashes.
FILENAME
RECTYPES
ALL specifies all record types are dumped. A logical expression can be specified to restrict the data records selected. The expression can reference common variables or variables from the listed record type and can include PQL functions.
BOOLEAN
BOOLEAN is applied after any SAMPLE, COUNT or LIST.
CIR
CIR to output common variables as a separate record (record type 0).
COUNT
SAMPLE or LIST. Total specifies the number of cases to retrieve. Increment specifies the "skipping factor" for retrieving cases. Start specifies the first case to select. For example, a start value of 3 begins the processing at the third case.
SIR FILE DUMP FILENAME = 'OUTPUT.DAT'
RECTYPES = ALL COUNT = 10
CSV
DPOINT
LIST
LIST cannot be used with SAMPLE or
COUNT. For example:
SIR FILE DUMP FILENAME = 'OUTPUT.DAT'
RECTYPES = ALL LIST = 1,3,5 thru 10
NOAUTO
SAMPLE
UNDEFINED
SIR FILE DUMP FILENAME = 'OUTPUT.DAT'
RECTYPES = 1 (SALARY GT 2000)
UNDEFINED = *
| |
SIR FILE LIST FILENAME=filename
[BOOLEAN= (log-expr)]
[LIST= caseid list]
[RECTYPES= rectype [(log-expr)] ...| ALL]
[ORDER= ALPHA | VARNUM]
[SAMPLE= fraction [,seed]]
[COUNT= total [,incr[,start]]]
[CIR= varlist | NOCIR]
[VARIABLES = rectype (var-list)]
Writes all or part of the data to a file for subsequent printing. Use the filename CONSOL to write to the screen or STDOUT to write to the default output file.DBA read security is required to use this utility.
BOOLEAN
LIST, COUNT or SAMPLE is used, the BOOLEAN clause is applied after that selection process. For example:
BOOLEAN = (ID GT 5)
LIST
LIST cannot be used with SAMPLE or COUNT. For example:
LIST= 1,3,5,7 to 10
RECTYPES
RECTYPES= ALL specifies all record types.
If RECTYPES is omitted from the command,
only the common variables are listed. A logical expression may be defined to
select particular data records within a record type. If the test is TRUE,
the record is listed. The expression may use common or record variables from the
record type. For example:
RECTYPES= 1 (GENDER=2)
ORDER
ALPHA) of the variable name or the order the variables are defined in the record (VARNUM). VARNUM is the default. For example:
SIR FILE LIST FILENAME='DATA.LIS' ORDER= ALPHA
SAMPLE
SAMPLE cannot be used with COUNT
or LIST. For example:
SIR FILE LIST FILENAME='DATA.LIS' SAMPLE= .5
COUNT
COUNT cannot be used with SAMPLE or LIST. For example:
SIR FILE LIST FILENAME='DATA.LIS' COUNT= 50,3,3
CIR
CIR
clause is omitted, all common variables are listed. For example:
SIR FILE LIST FILENAME='DATA.LIS' CIR= ID
NOCIR
SIR FILE LIST FILENAME='DATA.LIS' NOCIR
VARIABLES
SIR FILE LIST FILENAME='DATA.LIS' RECTYPE = 3
VARIABLES = 3 (position,revdate)
SIR/XS FILE LIST Jan 05, 2006 10:53:36 Page 1 ***CASE ID 1 REVIEW POSITION 4 REVDATE 04 05 03 POSITION 4 REVIEW POSITION 4 REVDATE 06 05 03 POSITION 4 REVIEW POSITION 5 REVDATE 12 09 04 POSITION 5 REVIEW POSITION 5 REVDATE 02 04 05 POSITION 5 ***CASE ID 2 REVIEW POSITION 6 REVDATE 03 16 03 POSITION 6 REVIEW POSITION 6 REVDATE 04 27 03 POSITION 6
| |
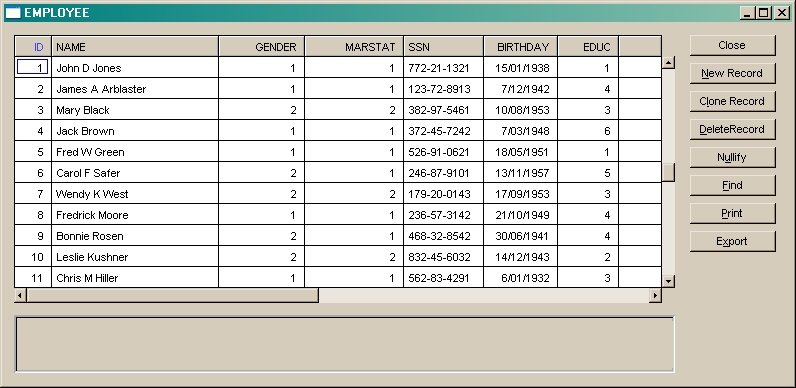
SIR SPREADSHEET
{RECTYPE = recname [BOOLEAN = (log-expr)] | TABLE=tabfile.table}
[INDEXED BY indexname]
[VARIABLES = (var1,var2,... | ALL)]
[LABELS|UPDATE]
Selects data from a single database record type or from a tabfile table and displays it in a graphical form similar to a spreadsheet display. The user can insert, delete or update if allowed, and can print or export the data in a CSV format
for input to other packages.
RECTYPE =
BOOLEAN = (logical_expression)
TABLE =
INDEXED BY (USING is a synonym)
VARIABLES
ALL is the default.LABELS (VALLAB is a synonym)
UPDATEUPDATE
For example:
SIR SPREADSHEET RECTYPE=EMPLOYEE BOOLEAN=(GENDER EQ 2) UPDATEThe record data is displayed as a spreadsheet that looks something like:
| |